mobilenet_SSD
雷达全场定位的模型主要是mobilenet_SSD,它能根据摄像头传回的图像,定位出机器人的位置,返回机器人的相对位置和红蓝分类。
mobilenet_SSD主要是两个很重要的模型组成,一个是mobilenet,一种新型的轻量级深度卷积神经网络;一个是SSD,single shot multibox detector,一种目标检测的模型。
因为深度学习神经网络涉及的内容很多,包括优化算法,反向传播,损失函数。每部分内容都有很多细节,占很大的篇幅,一次肯定讲不完,因此这次就先简单介绍一下计算机视觉里的深度学习的基础模型:卷积神经网络
在计算机视觉中,我们先从一张图像开始,主要是对图像做处理,其中最重要的就是提取图像的特征,而一张图像由若干个像素构成,如果是RGB图像,则每个像素点都是一个0~255范围内的数。因此可以将图片看成是一层层矩阵堆叠而成,称为张量。
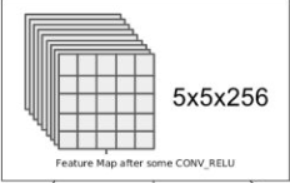
像上图一样的就称为张量,每一个小块就是一个像素点,这里是5x5大小的图像,也就是5x5的像素点,256层,因此就是5x5x256的张量。而一张RGB图像,就是由R、G、B三层矩阵构成,是width x height x 3的张量。
有了图像是张量的这个概念之后,我们就可以想象,一个图像的特征,从张量的角度看,就是张量中有特定组合的元素组成。然后卷积,就是用一个小矩阵,对张量以一定步长进行遍历并做哈达玛积,也就是很简单的:矩阵的元素对应相乘并求平均值,用这个过程遍历整张图就得到卷积后的结果,称为特征图。
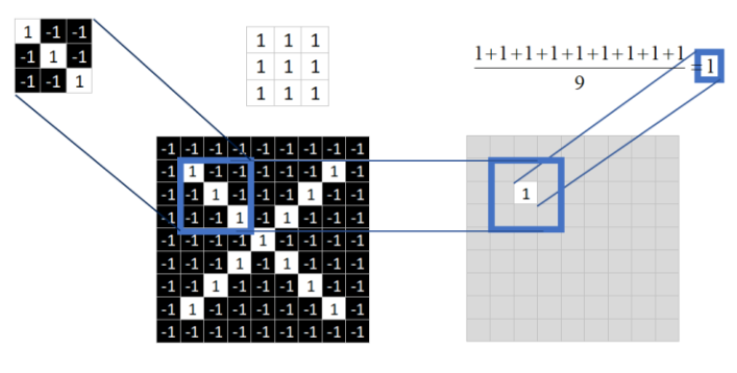
可以想象,这个过程就是一个特征提取的过程。显然也可以知道,卷积提取特征的结果与两个因素有关:一个是图像在被卷积区域的像素分布,一个是卷积核上的数值。卷积核上的数值可以通过训练进行修正,使卷积核上的数值能够更好的提取特征。而深度神经网络实际上是上面提到的过程以特定的有效方式重复进行。
而回到mobilenet_SSD,mobilenet为什么成为轻量级卷积神经网络。我们都知道算法都有复杂度,举个例子,两个循环的嵌套的时间复杂度是O($n^2$),但如果能把这两个循环嵌套拆开也能完成相同的任务,那么时间复杂度就变成O(n)了。mobilenet就是这样一个把传统的CNN中的标准卷积拆开,分为逐点卷积和深度卷积。来降低复杂度。
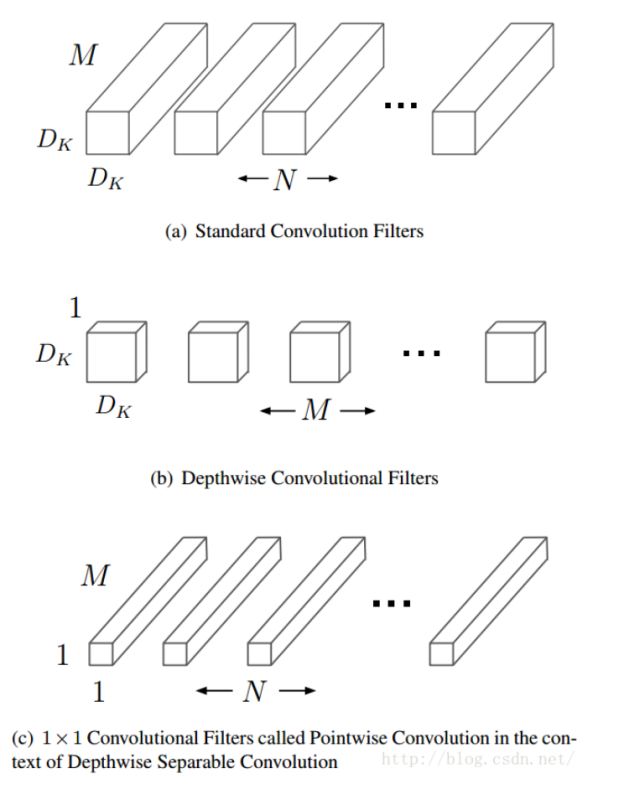
然后SSD,因为最终的效果是框出我们想要的物体在哪,因此SSD就先在图像以几个点为中心先生成几个框,称为先验框,对这个框围起来的图像进行卷积,计算分类的偏差和真实的框的偏差。
作者:杨扬
